原文标题: MemGPT: Towards LLMs as Operating Systems 作者: Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, Joseph E. Gonzalez 机构: 加州大学伯克利分校 arXiv: 2310.08560v2 [cs.AI] 2024年2月12日 翻译整理: 2025年2月
摘要
大语言模型(LLM)已经彻底改变了人工智能领域,但受到有限的上下文窗口限制,这阻碍了它们在扩展对话和文档分析等任务中的实用性。为了能够在有限的上下文窗口之外使用上下文,我们提出了虚拟上下文管理技术,这一技术借鉴了传统操作系统中的分层内存系统,通过物理内存和磁盘之间的分页来提供扩展虚拟内存的幻觉。
利用这一技术,我们引入了 MemGPT(MemoryGPT),这是一个能够智能管理不同存储层级的系统,以在 LLM 有限的上下文窗口内有效提供扩展上下文。我们在两个领域评估了受操作系统启发的设计,在这些领域中,现代 LLM 的有限上下文窗口严重限制了它们的性能:
- 文档分析:MemGPT 能够分析远超底层 LLM 上下文窗口的大型文档
- 多会话聊天:MemGPT 可以创建能够记住、反思并通过与用户的长期互动动态进化的对话智能体
我们在 https://research.memgpt.ai 发布了 MemGPT 代码和实验数据。
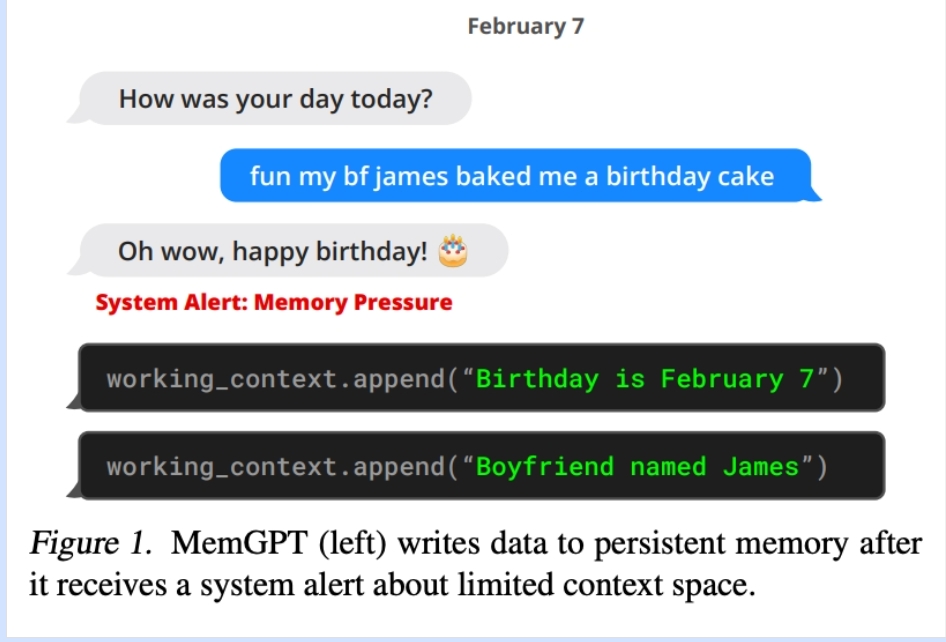 图 1. MemGPT(左)在收到关于有限上下文空间的系统警报后将数据写入持久内存。
图 1. MemGPT(左)在收到关于有限上下文空间的系统警报后将数据写入持久内存。
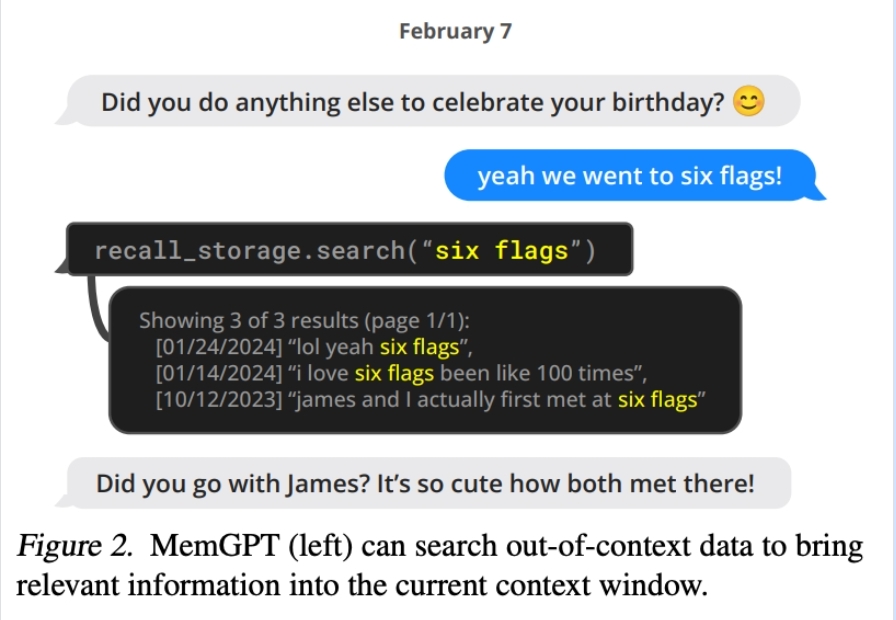 图 2. MemGPT(左)可以搜索上下文外数据,将相关信息带入当前上下文窗口。
图 2. MemGPT(左)可以搜索上下文外数据,将相关信息带入当前上下文窗口。
1. 引言
近年来,大语言模型(LLM)及其底层的 Transformer 架构(Vaswani et al., 2017; Devlin et al., 2018; Brown et al., 2020; Ouyang et al., 2022)已成为对话式人工智能的基石,并催生了广泛的消费者和企业应用。尽管取得了这些进展,LLM 使用的有限固定长度上下文窗口显著阻碍了它们对长对话或长文档推理的适用性。例如,最广泛使用的开源 LLM 只能支持几十轮来回消息或推理短文档,然后就会超过其最大输入长度(Touvron et al., 2023)。
直接扩展 Transformer 的上下文长度会导致计算时间和内存成本的二次方增长,这是由于 Transformer 架构的自注意力机制造成的,这使得新长上下文架构的设计成为一个紧迫的研究挑战(Dai et al., 2019; Kitaev et al., 2020; Beltagy et al., 2020)。虽然开发更长的模型是一个活跃的研究领域(Dong et al., 2023),即使我们能够克服上下文扩展的计算挑战,最近的研究表明长上下文模型难以有效利用额外的上下文(Liu et al., 2023a)。
因此,考虑到训练最先进 LLM 所需的大量资源以及上下文扩展的收益递减,迫切需要替代技术来支持长上下文。在本文中,我们研究了如何在使用固定上下文模型的同时提供无限上下文的幻觉。我们的方法借鉴了虚拟内存分页的思想,该技术通过主内存和磁盘之间的数据分页,使应用程序能够处理远超可用内存的数据集。我们利用 LLM 智能体函数调用能力的最新进展(Schick et al., 2023; Liu et al., 2023b)来设计 MemGPT。
2. MemGPT(MemoryGPT)
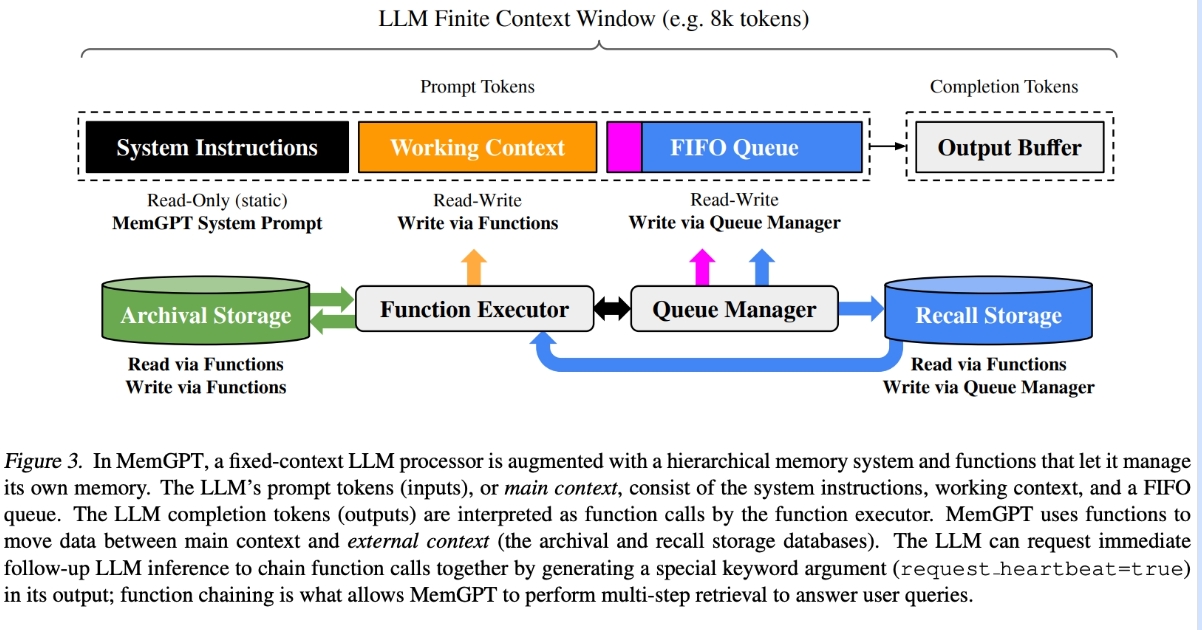 图 3. 在 MemGPT 中,固定上下文 LLM 处理器通过分层内存系统和函数进行增强,使其能够管理自己的内存。LLM 的提示词令牌(输入)或主上下文由系统指令、工作上下文和 FIFO 队列组成。LLM 完成令牌(输出)被函数执行器解释为函数调用。MemGPT 使用函数在主上下文和外部上下文(归档和回忆存储数据库)之间移动数据。
图 3. 在 MemGPT 中,固定上下文 LLM 处理器通过分层内存系统和函数进行增强,使其能够管理自己的内存。LLM 的提示词令牌(输入)或主上下文由系统指令、工作上下文和 FIFO 队列组成。LLM 完成令牌(输出)被函数执行器解释为函数调用。MemGPT 使用函数在主上下文和外部上下文(归档和回忆存储数据库)之间移动数据。
MemGPT 的受操作系统启发的多级内存架构区分了两种主要内存类型:
- 主上下文(类似于主内存/物理内存/RAM)
- 外部上下文(类似于磁盘内存/磁盘存储)
主上下文由 LLM 提示词令牌组成–主上下文中的任何内容都被视为上下文内,可以在推理期间被 LLM 处理器访问。外部上下文指的是保持在 LLM 固定上下文窗口之外的任何信息。这种上下文外数据必须始终被显式移动到主上下文中,才能在推理期间传递给 LLM 处理器。
MemGPT 提供函数调用,使 LLM 处理器能够管理自己的内存,无需任何用户干预。内存层级、操作系统函数和基于事件的控制流的结合使用使 MemGPT 能够使用具有有限上下文窗口的 LLM 处理无界上下文。
2.1 主上下文(提示词令牌)
MemGPT 中的提示词令牌分为三个连续部分:
- 系统指令:只读(静态),包含有关 MemGPT 控制流、不同内存级别的预期用途以及如何使用 MemGPT 函数的信息
- 工作上下文:固定大小的读/写非结构化文本块,仅通过 MemGPT 函数调用可写。在对话设置中,工作上下文用于存储关于用户和智能体所采用角色的关键事实、偏好和其他重要信息,使智能体能够与用户流利地对话
- FIFO 队列:存储消息的滚动历史,包括智能体和用户之间的消息,以及系统消息和函数调用输入和输出。FIFO 队列中的第一个索引存储包含已从队列中逐出的消息的递归摘要的系统消息
2.2 队列管理器
队列管理器管理回忆存储和 FIFO 队列中的消息。当系统收到新消息时,队列管理器将传入消息附加到 FIFO 队列,连接提示词令牌并触发 LLM 推理以生成 LLM 输出。队列管理器将传入消息和生成的 LLM 输出都写入回忆存储(MemGPT 消息数据库)。
当通过 MemGPT 函数调用检索回忆存储中的消息时,队列管理器将它们附加到队列的后面,以将它们重新插入 LLM 的上下文窗口。队列管理器还负责通过队列逐出策略控制上下文溢出。当提示词令牌超过底层 LLM 上下文窗口的"警告令牌计数"(例如上下文窗口的 70%)时,队列管理器在队列中插入系统消息,警告 LLM 即将发生的队列逐出(“内存压力"警告),以允许 LLM 使用 MemGPT 函数将 FIFO 队列中的重要信息存储到工作上下文或归档存储。
3. 实验
我们在两个长上下文领域评估 MemGPT:对话智能体和文档分析。对于对话智能体,我们扩展了现有的多会话聊天数据集(Xu et al., 2021),并引入了两个新的对话任务,评估智能体在扩展对话中保留知识的能力。对于文档分析,我们在 Liu 等人(2023a)的现有任务上对 MemGPT 进行基准测试,用于对冗长文档进行问答和键值检索。
 图 4. 一个对话片段示例,MemGPT(左)更新存储的信息。这里信息存储在工作上下文内存中(位于提示词令牌内)。
图 4. 一个对话片段示例,MemGPT(左)更新存储的信息。这里信息存储在工作上下文内存中(位于提示词令牌内)。
3.1 MemGPT 用于对话智能体
对话智能体(如虚拟伴侣和个性化助手)旨在与用户进行自然的长期互动,可能持续数周、数月甚至数年。这为具有固定长度上下文的模型创造了挑战,这些模型只能引用有限的对话历史。“无限上下文"智能体应无缝处理连续交流,没有边界或重置。
3.1.1 深度记忆检索任务(一致性)
我们基于 MSC 数据集引入了一个新的"深度记忆检索”(DMR)任务,旨在测试对话智能体的一致性。在 DMR 中,用户向对话智能体提出一个明确引用先前对话的问题,并具有非常狭窄的预期答案范围。我们使用 LLM 生成 DMR 问答对,并用 ROUGE-L 分数和"LLM 评判"来评估生成响应的质量。
表 1:深度记忆检索(DMR)性能
| 模型 | 准确率 ⇑ | ROUGE-L (R) ⇑ |
|---|---|---|
| GPT-3.5 Turbo | 38.7% | 0.394 |
| + MemGPT | 66.9% | 0.629 |
| GPT-4 | 32.1% | 0.296 |
| + MemGPT | 92.5% | 0.814 |
| GPT-4 Turbo | 35.3% | 0.359 |
| + MemGPT | 93.4% | 0.827 |
3.1.2 对话开场白任务(参与度)
我们评估智能体利用先前对话中积累的知识制作吸引人的消息的能力。为了评估对话开场白的"参与度”,我们将生成的开场白与 gold personas 进行比较。
表 2:对话开场白性能
| 方法 | SIM-1 | SIM-3 | SIM-H |
|---|---|---|---|
| 人工 | 0.800 | 0.800 | 1.000 |
| GPT-3.5 Turbo | 0.830 | 0.812 | 0.817 |
| GPT-4 | 0.868 | 0.843 | 0.773 |
| GPT-4 Turbo | 0.857 | 0.828 | 0.767 |
MemGPT 能够制作与人工编写的开场白相当甚至超过的吸引人的开场白。我们观察到 MemGPT 倾向于制作比人工基线更冗长且涵盖更多角色信息方面的开场白。
3.2 MemGPT 用于文档分析
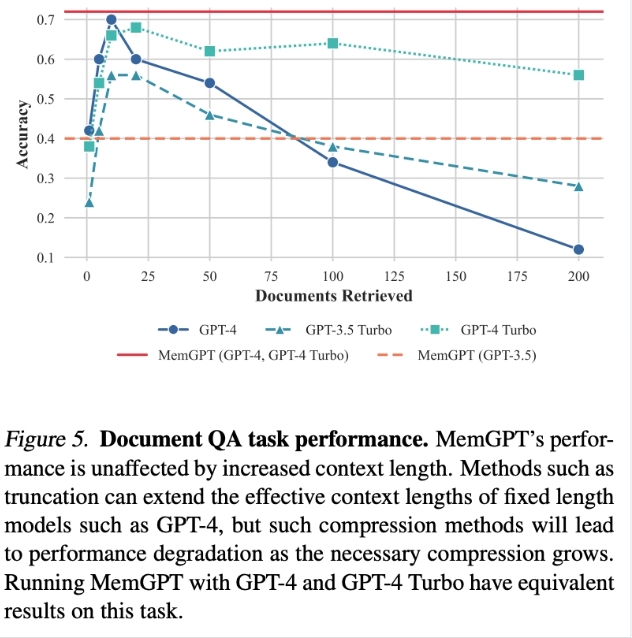 图 5. 文档 QA 任务性能。MemGPT 的性能不受上下文长度增加的影响。使用 GPT-4 和 GPT-4 Turbo 运行 MemGPT 在此任务上具有等效的结果。
图 5. 文档 QA 任务性能。MemGPT 的性能不受上下文长度增加的影响。使用 GPT-4 和 GPT-4 Turbo 运行 MemGPT 在此任务上具有等效的结果。
文档分析也面临着当今 Transformer 模型有限上下文窗口的挑战。如表 3 所示,开源和闭源模型都受到上下文长度的限制(OpenAI 的模型最多 128k 令牌)。然而许多文档轻松超过这些长度;例如,法律或财务文件(如年度报告)可能轻松超过百万令牌。
表 3:常用模型和 LLM API 的上下文长度比较
| 模型 / API | 开放? | 上下文窗口(令牌) | 大约消息数* |
|---|---|---|---|
| Llama (1) | ✓ | 2k | 20 |
| Llama 2 | ✓ | 4k | 60 |
| GPT-3.5 Turbo | ✗ | 16k | 300 |
| GPT-4 | ✗ | 32k | ~600 |
| Claude 2 | ✗ | 100k | ~2600 |
| GPT-4 Turbo | ✗ | 128k | ~4000 |
*假设预提示为 1k 令牌,平均消息大小为 ~50 令牌(~250 个字符)
3.2.1 多文档问答
 图 6. MemGPT(左)解决文档 QA 任务的示例。维基百科文档数据库上传到归档存储。MemGPT 通过函数调用查询归档存储,将分页搜索结果拉入主上下文。
图 6. MemGPT(左)解决文档 QA 任务的示例。维基百科文档数据库上传到归档存储。MemGPT 通过函数调用查询归档存储,将分页搜索结果拉入主上下文。
为了评估 MemGPT 分析文档的能力,我们在来自 Liu 等人的检索器-阅读器文档 QA 任务上对 MemGPT 进行基准测试。MemGPT 的性能不受上下文长度增加的影响。虽然截断等方法可以扩展固定长度模型(如 GPT-4)的有效上下文长度,但随着所需压缩的增长,这种压缩方法将导致性能下降。
3.2.2 嵌套键值检索(KV)
我们引入了一个基于先前工作中提出的合成键值检索的新任务。在这个任务的嵌套版本中,值本身可能是键,因此需要智能体执行多跳查找。
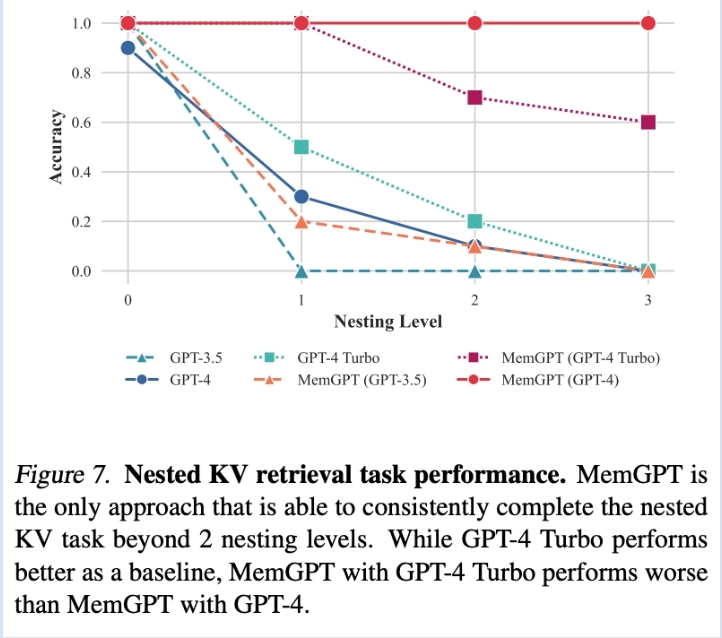 图 7. 嵌套 KV 检索任务性能。MemGPT 是唯一能够在超过 2 级嵌套的情况下始终如一地完成嵌套 KV 任务的方法。
图 7. 嵌套 KV 检索任务性能。MemGPT 是唯一能够在超过 2 级嵌套的情况下始终如一地完成嵌套 KV 任务的方法。
 图 8. MemGPT(左)解决嵌套 KV 任务的示例(为可读性缩短了 UUID)。在这个特定示例中,键值对有两个嵌套级别:831..ea5 → 5b8..4c3 → f37…617。当对最终值的查询只返回一个结果时,MemGPT 智能体返回最终答案,表明它也不是键。
图 8. MemGPT(左)解决嵌套 KV 任务的示例(为可读性缩短了 UUID)。在这个特定示例中,键值对有两个嵌套级别:831..ea5 → 5b8..4c3 → f37…617。当对最终值的查询只返回一个结果时,MemGPT 智能体返回最终答案,表明它也不是键。
结果:
- GPT-3.5 在 1 级嵌套时准确率降至 0%
- GPT-4 和 GPT-4 Turbo 在 3 级嵌套时准确率降至 0%
- MemGPT 与 GPT-4 不受嵌套级别数量的影响,能够通过函数查询重复访问存储在主上下文中的键值对来执行嵌套查找
4. 相关工作
**长上下文 LLM:**几条工作线改进了 LLM 的上下文长度。例如,通过稀疏化注意力(Child et al., 2019; Beltagy et al., 2020)、低秩近似(Wang et al., 2020)和神经内存(Lee et al., 2019)实现更高效的 Transformer 架构。MemGPT 建立在这些上下文长度改进的基础上,因为它们提高了 MemGPT 中主内存的大小。
**检索增强模型:**MemGPT 的外部内存设计借鉴了大量使用外部检索器增强 LLM 的相关工作(Ram et al., 2023; Borgeaud et al., 2022; Karpukhin et al., 2020; Lewis et al., 2020; Guu et al., 2020)。特别是,Jiang 等人(2023)提出了 FLARE,一种允许 LLM 在生成过程中主动决定何时以及检索什么的方法。
**作为智能体的 LLM:**最近的工作探索了增强 LLM 的能力,使其能够在交互式环境中充当智能体。Park 等人(2023)提出向 LLM 添加内存并使用 LLM 作为规划器。与我们的工作相反,这些工作侧重于为智能体配备用户输入的长期记忆。
5. 结论
在本文中,我们介绍了 MemGPT,一种受操作系统启发的新型 LLM 系统,用于管理大语言模型的有限上下文窗口。通过设计类似于传统操作系统的内存层级和控制流,MemGPT 为 LLM 提供了更大上下文资源的幻觉。这种受操作系统启发的方法在两个领域进行了评估,其中现有 LLM 的性能受到有限上下文长度的限制:文档分析和对话智能体。
对于文档分析,MemGPT 能够通过有效地将相关上下文分页进出内存来处理远超当前 LLM 上下文限制的长文本。对于对话智能体,MemGPT 能够在扩展对话中保持长期记忆、一致性和可进化性。总的来说,MemGPT 证明了操作系统技术(如分层内存管理和中断)即使在受固定上下文长度限制时也能释放 LLM 的潜力。
这项工作为未来的探索开辟了众多途径,包括将 MemGPT 应用于其他具有大量或无界上下文的领域,集成不同的内存层技术(如数据库或缓存),以及进一步改进控制流和内存管理策略。通过将操作系统架构的概念引入 AI 系统,MemGPT 代表了在其基本限制内最大化 LLM 能力的有希望的新方向。
核心贡献总结
- **虚拟上下文管理:**首次将 OS 虚拟内存思想应用于 LLM,实现无限上下文的幻觉
- **分层存储管理:**主上下文 ↔ 外部存储的自动交换,类似于 CPU 缓存层次结构
- **中断驱动控制流:**函数调用作为"系统中断",让 Agent 主动管理内存
- **生产就绪系统:**完整的 API、SDK 和 CLI 工具链
引用信息
@article{packer2023memgpt,
title={{MemGPT}: Towards LLMs as Operating Systems},
author={Packer, Charles and Wooders, Sarah and Lin, Kevin and
Fang, Vivian and Patil, Shishir G. and Stoica, Ion and
Gonzalez, Joseph E.},
journal={arXiv preprint arXiv:2310.08560},
year={2023}
}
相关资源
- 官网: https://letta.ai
- 文档: https://docs.letta.com
- GitHub: https://github.com/letta-ai/letta
- 论文: https://research.memgpt.ai
- Discord: https://discord.gg/letta
中文翻译整理完成于 2025年2月 原文: arXiv:2310.08560 [cs.AI] 翻译说明:本翻译保留了原文的所有图表、表格结构和关键术语,同时提供了完整的中文解释