原文来源:https://mp.weixin.qq.com/s/FHdGHztSOOItttUYwA9dQw
Cursor长时间运行 Agent 的工程方法论
引言
Cursor 在做一件很明确、也很少有人把它“工程化讲清楚”的事:让编码 Agent 以周为单位持续自主工作,并把并发扩展到数百级,观察系统在真实代码库里如何推进、如何失效、如何恢复。
本文不做内容复述,重点分析 Cursor 的关键行为与工程选择:他们如何从平权协作的失败中抽象出分层结构,如何把质量控制外置到评估闭环,如何用重启机制对抗漂移,以及这些选择对工程团队意味着什么。
太长不看版
- 核心行为链:单 Agent 在复杂项目里变慢 → 平权协作失败(锁/脆弱/空转)→ 分层流水线(Planner/Worker/Judge)→ 用“重启 + 评估”对抗漂移 → 在多组长跑实验中获得可行性证据。
- 并发扩展的最大阻力集中在三处:协作机制、收敛信号(评估闭环)、漂移控制。缺一项都会把成本放大到吞噬吞吐。
- 工程关键选择集中在“外部化质量控制”:把质量与收敛交给 CI/基准/扫描等门禁,减少串行集成瓶颈。
- 提示体系承担了“组织制度”的作用,需要版本化、可审计、可回滚;Cursor 在实践中把提示的影响放在了很高优先级。
- 浏览器等大体量实验更适合作为边界证明,不适合作为评价指标。评价指标应围绕可构建、可验证、可演进展开。
1. 工程术语:长跑、漂移与收敛信号
为了避免讨论停留在口号层面,先把三个概念明确化。
1)长时间运行(Long-running)
同一目标跨多轮迭代持续推进(小时/天/周),并在多次上下文刷新后保持约束一致性。这里的难点主要落在“约束保持”和“收敛判据”上。
2)漂移(Drift)
目标、约束或策略在长时间运行中发生偏移,常见症状包括:反复重写、低价值优化、偏离验收标准、只修表象不修根因。
3)收敛信号(Evaluation Signals)
能客观判断“是否更接近目标”的证据,例如:构建产物、测试通过率、回归基准、崩溃率趋势、安全扫描结果、性能指标曲线。
落地时,团队需要优先回答两个问题:
- 交付目标能否被表达为可检查的约束与可度量的验收信号。
- 失败能否被快速分类为“可重试/需重启/需人工介入/需降级方案”。
2. 单个 Agent 的局限:并发扩展的动机
Cursor 的出发点很务实:Agent 做小任务表现不错,复杂项目推进速度会明显下降。并行运行多个 Agent 是自然选择,但“如何协调”本身会变成主成本。
这里有一个容易忽略的细节:作者没有把“先做一套完备规划”当作默认解法。原因在于大型项目的路径并不明确,早期拆分也很难一次到位。于是系统从动态协调入手,让 Agent 根据其他 Agent 当前在做的事情决定下一步。
工程含义很直接:任务拆解与协作策略会持续演化,系统需要允许“边跑边重写计划”,并为这种变化提供机制支撑。
3. 学习如何协同:锁、乐观并发控制与空转
最有价值的部分之一,是把失败过程公开出来。
3.1 平权协作 + 共享状态 + 锁
所有 Agent 地位相同,通过共享文件查看状态、认领任务并更新状态。为了避免抢占,引入锁机制。
失效点也很典型:
- 锁持有时间过长或忘记释放,直接把并发吞吐压扁,出现“20 个 Agent 的有效吞吐接近 2–3 个”的现象。
- 系统脆弱,持锁崩溃、重复加锁、无锁写入都会破坏一致性。
3.2 乐观并发控制(OCC)
允许自由读取状态,写入时检查状态是否变化,变化则写入失败。健壮性更好,但更深层问题仍存在:
- 缺少层级结构时,Agent 会倾向于规避风险,只做小而安全的改动。
- 没有明确责任承载者,困难任务无人推进,系统进入长时间空转。
这一段对架构师很重要:并发系统的问题不只来自冲突,还来自“选择偏差”,大量算力被消耗在边际收益极低的动作上。
4. 关键转折:Planner / Worker / Judge 的分层流水线
Cursor 最终选择了最小可行的分层结构:
- 规划者(Planner):持续探索代码库并创建任务;可派生子规划者,使规划过程递归并行。
- 执行者(Worker):领取任务并端到端完成;不做全局协调,只对任务负责;完成后提交变更。
- 评审者(Judge):每个周期结束评估是否继续;下一轮从干净状态重新开始,用重启对抗漂移与视野收缩。
用一张流程图把职责边界画清楚:
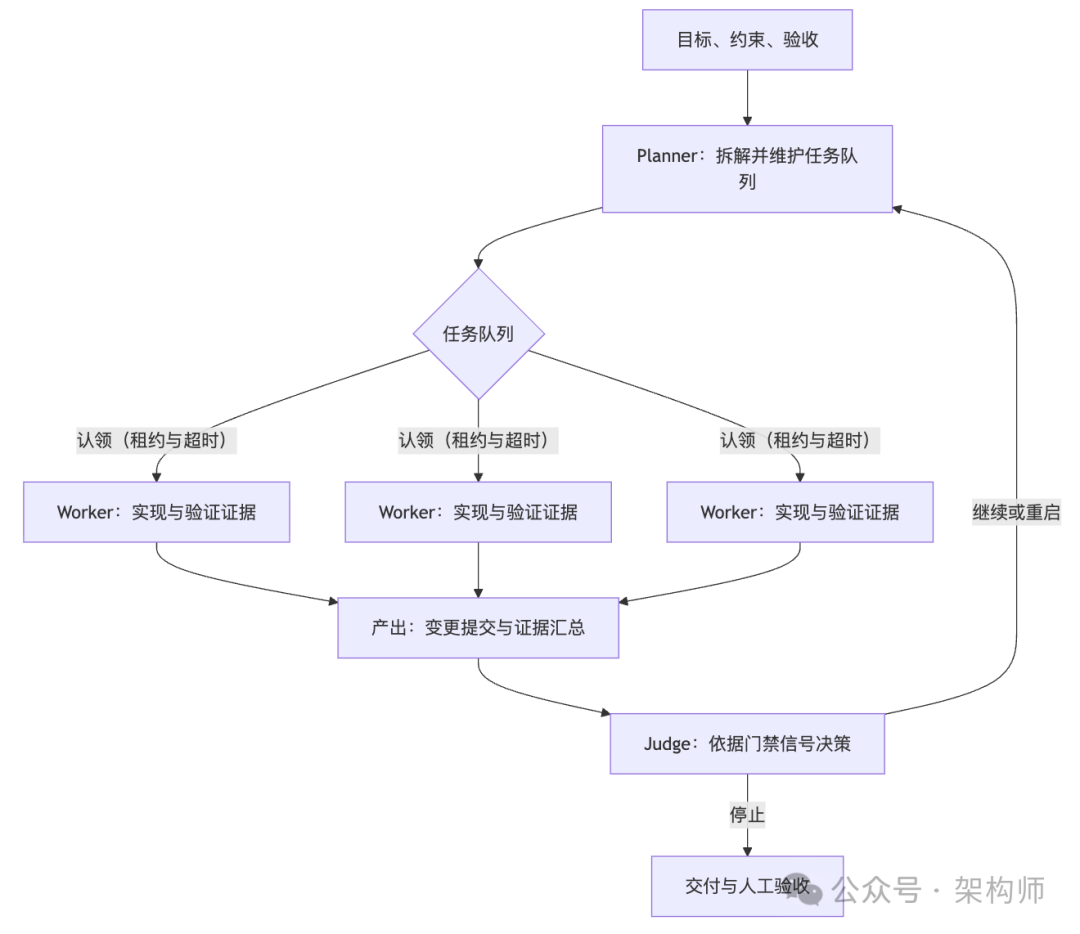
这套结构的工程意义主要体现在两点:
- 责任边界明确后,系统不再依赖每个 Agent 同时承担探索、拆分、实现、合并的多重角色。
- 评估点显式化后,“继续/停止/重启”变成机制而非直觉,长跑可控性会显著提升。
5. 运行数周之久:如何解读那些“很大”的数字
Cursor 给出多组长跑实验来证明可行性:
- 从零构建浏览器:持续近一周,在约 1,000 个文件中写出超过 100 万行代码,并给出源码(FastRender)。
- Solid → React 迁移:持续 3 周多,代码增删量
+266K/-193K,并能通过 CI 与早期检查。 - 关键路径优化:通过 Rust 实现把视频渲染速度提升 25 倍,并补齐缩放/平移与动效,代码已合并准备上线。
- 仍在运行的项目:Java LSP、Windows 7 模拟器、Excel 等,提供了提交数与 LoC 量级。
工程评估时,这些数字更适合作为“能力边界证明”,不适合作为 KPI。KPI 需要围绕交付信号展开:
| 维度 | 建议指标(示例) | 目的 |
|---|---|---|
| 构建可复现 | 构建成功率、依赖锁定、可复现构建时间 | 保障可交付 |
| 质量收敛 | 测试通过率、flake 比例、缺陷回归率 | 保障可靠性 |
| 合并吞吐 | PR 合并周期、冲突率、回滚/重做率 | 保障效率 |
| 可维护性 | 变更集中度、模块边界稳定性、接口变更频次 | 保障演进 |
| 运行表现 | 性能基准、资源占用、崩溃率趋势 | 保障体验 |
| 安全合规 | secret 命中、依赖漏洞、权限越界事件 | 保障治理 |
6. 我们学到了什么:把经验落成可执行规则
这些结论对落地策略影响很大,更适合直接转写成工程规则。
6.1 按角色选模型
Cursor 指出模型选择对长时间任务非常关键,并观察到 GPT-5.2 系列更能遵循指令、保持专注、避免偏离,实现更完整;同时不同模型在不同角色上各有所长,因此采用“按角色选型”,而不是单一模型通吃。
可执行规则:
- Planner 的评价指标偏向“拆解质量、约束保持、计划更新频率”。
- Worker 的评价指标偏向“实现完整性、验证证据质量、回归风险”。
- Judge 的评价指标偏向“收敛速度、失败分类准确率、重试成本”。
6.2 简化优先于加角色
Cursor 曾引入“集成者”做质量控制与冲突解决,但该角色制造的瓶颈大于收益,最终移除,由 Worker 自行处理冲突。
可执行规则:
- 质量控制尽量外置到门禁体系(CI/扫描/基准),减少串行“集成人”。
- 并发系统先解决背压与收敛,再讨论增加角色。
6.3 结构化要落在两端之间
Cursor 强调结构太少会冲突、重复、偏离;结构太多会脆弱。落地时,结构化应集中在“任务表达、门禁信号、权限治理”三处,其余部分保持可演化。
6.4 提示体系需要工程化治理
Cursor 明确提出提示会显著影响协作与长期专注。落地时更稳的做法是为不同角色建立 Prompt Contract,并对其版本化与审计。
7. 争议与校准:把外部叙事转换为工程信号
外部讨论通常会被两类叙事拉扯:
- 一类聚焦“规模与速度”,偏好用运行时长、代码量、并发数作为证明。
- 另一类聚焦“可用与可维护”,会追问能否编译、能否通过 CI、后续如何维护,以及是否存在大规模 AI 垃圾代码风险。
把叙事转换为工程信号后,结论会稳定很多:
- 代码量与文件数只能证明“系统能持续生成变更”,不足以证明“系统能持续交付可维护的软件”。
- “能否编译、能否通过 CI、能否上线”属于强信号,应该优先于任何叙事性指标。
- 争议本身很正常,它提醒团队把门禁与治理前置,避免把不确定性规模化。
团队内部做信息同步时,可以采用三问法:
- 这条信息对应哪类收敛信号(构建/测试/基准/安全/上线)?
- 缺失的关键信号是什么(例如缺少可复现构建、缺少端到端用例、缺少性能基准)?
- 若信号缺失,下一步如何补齐(新增测试、建立基准、补充回滚方案、降低权限)?
8. 应用场景与边界:哪些任务更适合“长跑 Agent”
Cursor 展示的案例覆盖了“从零构建”“大迁移”“性能攻坚”,但并不代表所有任务都适合直接采用长跑体系。下面给出一张工程侧适配表,用于判断投入产出:
| 场景 | 适配度 | 理由 | 推荐门禁信号 |
|---|---|---|---|
| 明确缺陷修复(可复现) | 高 | 现象清晰,收敛信号强 | 回归用例、日志对照、E2E |
| 性能热点优化 | 高 | 指标可量化,收益可验证 | 基准趋势线、资源占用、回滚开关 |
| 大规模迁移(框架/组件) | 中高 | 任务可拆,风险在合并与回归 | CI 分层、契约测试、兼容矩阵 |
| 基础设施自动化(脚手架/迁移工具) | 中 | 边界清晰,但需严格权限 | 最小权限、依赖审计、产物签名 |
| 交互与产品形态探索 | 低 | 验收主观,漂移概率高 | 人工评审点、设计稿对照、实验开关 |
| 高合规领域改造(金融/医疗核心链路) | 低 | 风险高,错误成本大 | 审计、双人复核、灰度与回滚体系 |
长期运行系统的第一批落地点,建议落在“收敛信号最强”的任务上,让 Judge 的决策尽快拥有可依赖的证据。
此外,长跑体系建议显式化“迭代周期”的节奏。以一个最小循环为例:
Judge门禁(CI/基准/扫描)WorkerPlannerJudge门禁(CI/基准/扫描)WorkerPlanner下发任务卡(目标/约束/验收/回滚)构建/测试/基准/扫描信号(通过/失败+原因)提交产出+验证证据分类失败(可重试/需重启/需人工)继续/停止/重启+下一轮策略
9. 最小系统清单:把“结构”做成可运行组件
落地一个长跑多智能体系统,最小编排面通常包含:
- 状态存储:任务队列、任务状态机、失败原因分类、Prompt 版本、产出引用(commit/PR/日志)。
- 并发控制:任务认领使用租约(lease)+ 超时回收;写入状态采用乐观并发;避免全局锁。
- 代码库接口:检出/构建/测试/基准/扫描的标准化入口,保证不同 Worker 的执行环境一致可复现。
- 产出通道:单分支推送或“每任务一 PR”;配套背压(并发上限、PR 规模阈值、评审吞吐阈值)。
- Judge 执行器:汇总门禁信号并给出决策;触发重试/重启;生成变更摘要与风险提示。
- 重启机制:定期清理工作区与上下文并重新拉起;重启后强制再扫描与再对齐约束。
组件目标是保持系统轻量,同时把三件事显式化:协作机制、收敛信号、漂移控制。
结语
Cursor 的工作最值得借鉴的一点,在于它把“Agent 写代码”推进到“以组织形态持续交付”的层面,并给出了一条可复现的演化路径:先暴露协作失败,再引入分层分工与评估点,最后用重启策略对抗长期漂移。
工程团队若要从热度走向生产,关注点需要稳定落在三处:协作结构是否可扩展、评估闭环是否足够强、治理与权限是否能承受规模化并发。
参考链接
- Cursor:扩展长时间运行的自主编码能力:https://cursor.com/cn/blog/scaling-agents
- FastRender(浏览器实验):https://github.com/wilsonzlin/fastrender