原文来源:https://mp.weixin.qq.com/s/WZWZsMCQHXKUGJKOS-VXDA
做RAG交付快2年了,一直被困扰就是各种Chunk,前一段时间开源的PageIndex给了我一些思考。直到最近爆火的Skill技术出现,让我想到了另一种实现思路,RAG问答是否可以采用 Skill 的渐进式加载方式呢?
在 Cursor / Claude 的 Skill 机制里,模型不会一上来把 SKILL.md 和所有 references 全塞进上下文,而是需要用到这个能力时再加载:先根据描述判断要不要用这个 Skill,用到了才去读 SKILL.md,遇到 PDF/Excel 再按规则去读 pdf_reading.md、excel_reading.md 这类参考文档。按需读、分层读、用到哪读到哪。我就在想,知识库检索能不能也这么干?不要一上来就全量切块、向量检索、一次 top-k 塞进上下文,而是先判断该看哪,再一点一点把需要的内容加载进来。于是有了这套「分层索引导航 + 渐进式检索」的本地知识库 Skill,和传统 RAG 走的是两条路。
从 Skill 的渐进式加载得到的启发
Skill 的用法是这样:模型先看 Skill 的简短描述,决定要不要激活;激活后才读 SKILL.md 里的流程和规则。规则里会写「处理 PDF 前必须先读 references/pdf_reading.md」,所以只有真要动 PDF 时才会去读那篇文档。结果就是不会一次性把所有材料都灌进上下文,而是按步骤、按类型、需要什么加载什么。
把同样的思路挪到知识库上:
- 分层加载:先读根目录的 FileIndex.md,知道有几大块(安全、财报、电商、AI 报告……),根据问题只进相关的那几块。进到子目录再读该层的 FileIndex.md,只加载可能用到的文件说明。用多级「小索引」代替一次把整库的向量都考虑进来。
- 按类型、按需加载:确定要查某类文件(比如 PDF)之后,才去读「怎么处理 PDF」的 references,再用学到的方法提取、检索,只把命中的片段读进上下文。Excel、Markdown 同理,用到再加载处理方法,再加载具体内容。
- 按轮次、小步加载:单轮只做一次定位加一小段上下文,不够就下一轮换关键词或换文件,最多 5 轮。每一轮都是加载一点、判断一下、再决定下一步,而不是一次 top-k 定生死。
检索流程就是先导航(读索引),再按类型学方法(读 references),再在选定范围里精查(grep + 局部 read),多轮迭代。下面把这条链路写细一点,再和传统 RAG 对比。
这套 Skill 在干什么:分层索引导航 + 渐进式检索
不建向量库,用「目录索引 + 按类型处理 + 关键词 + 局部读取」把要用的内容一点点加载进来。
1. 用「索引文件」代替「向量检索」做导航
每个目录(或子目录)里放一个 FileIndex.md,用自然语言写清楚:这里有哪些子目录、哪些文件、分别是干什么的、适合什么问题。根目录的 FileIndex.md 列出「安全知识」「财报」「电商数据」「AI 报告」等几大块;进到「AI 报告」再读该目录下的 FileIndex.md,列出具体 PDF 名称和用途。
检索时先读这些索引,根据用户问题选最可能相关的目录或文件,再只在这些目标上做后续动作。用人工写的目录替代「用向量相似度猜该看哪」。
2. 按文件类型分别处理,且「先学再动手」
- PDF:不直接整本塞给模型。先按规范(写在 references 里)用 pdftotext 或 pdfplumber 把文本或表格提出来,写到临时文件;再用 grep 在文本里找关键词,只读命中附近的片段。
- Excel:先学「怎么用 pandas 读、怎么限制 nrows/列」,再按问题筛选列、按条件过滤行,只读需要的那几块。
- Markdown/文本:用 grep 定位关键词,按行号做局部 read,不整文件拉进来。
规则里有一条硬性要求:凡是要动 PDF/Excel,必须先读对应的 references 文档,避免乱试、乱整文件、乱占 token。
3. 渐进式、多轮检索,且控制读取范围
用关键词(grep)而不是向量相似度在已选定的文件里找。对每个命中,只读匹配行附近的一小段(例如前后各几十行),用 offset + limit 控制。一轮不够就多轮(我们设了最多 5 轮):换关键词、换文件、收窄或扩大范围,直到够答或明确答不了。
先靠索引缩小到少数文件,再在这些文件里用关键词和局部读取精确定位,不整文件、不整本 PDF、不整张表进上下文。和 Skill 一样,先判断再按需读。
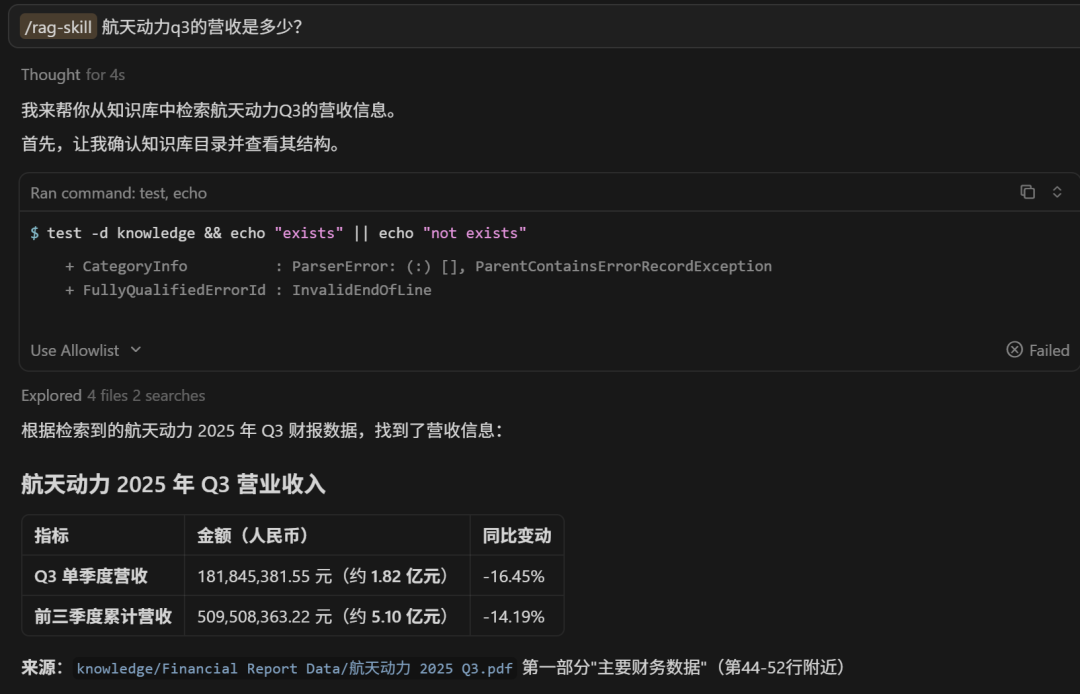
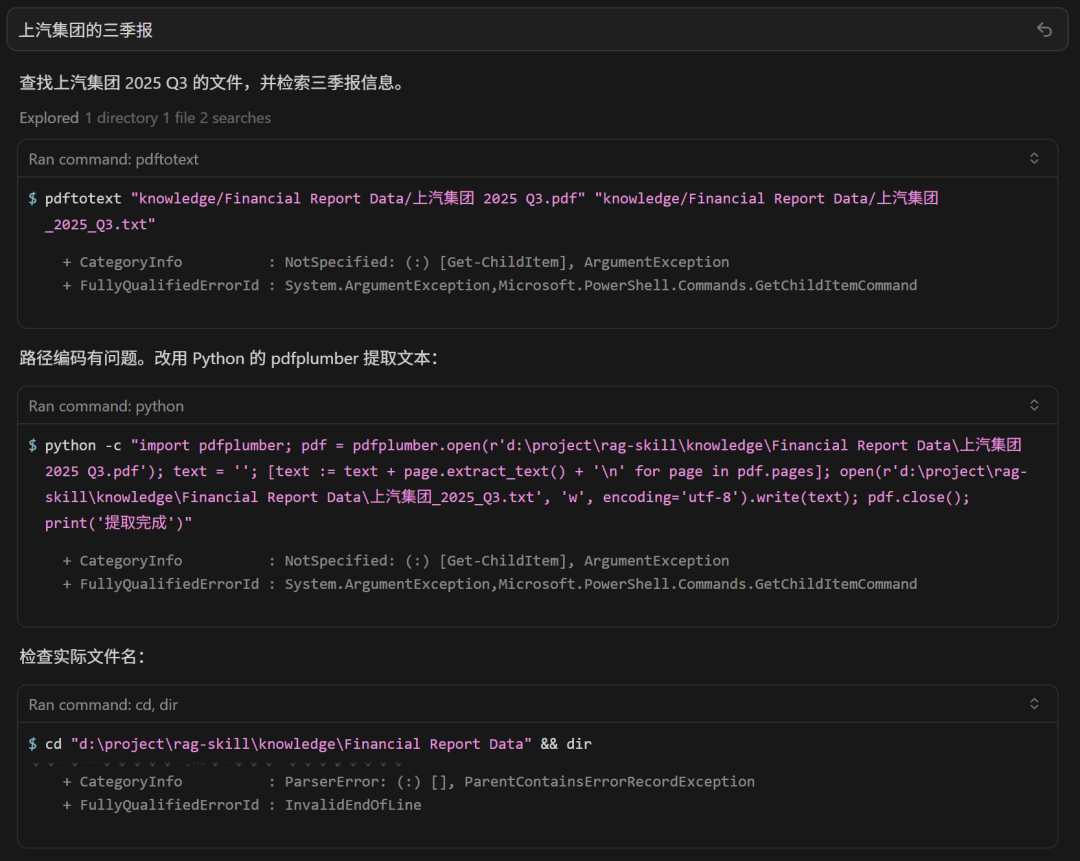
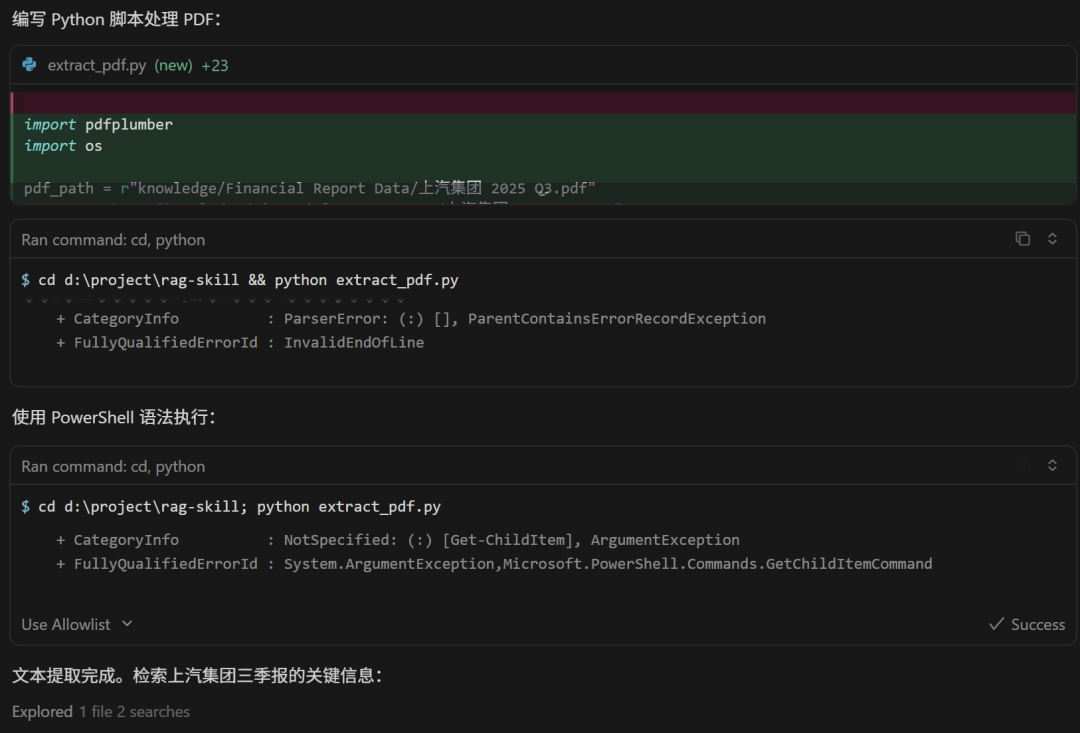

另一条路:传统 RAG 在干什么
和「渐进式加载」相反,传统 RAG 走的是预处理全量、查询时一次捞够的路线:
1. 预处理:把文档切成 chunk,每块算向量,存进向量数据库。
- 提问时:把问题也变成向量,在库里做相似度检索,取 top-k 个最「像」的块。
- 拼上下文:把这 k 个块(有时再重排)和问题一起塞进大模型。
- 生成答案:模型基于这些片段回答。
语义检索强,换一种说法也能找到意思相近的内容,适合开放域、问法多样的场景。代价是要选 embedding 模型、搭向量库、定 chunk 策略,文档更新要重算向量、重建索引。对「本地一堆 PDF/Excel/Markdown、目录清晰、希望少维护」的场景,会有点重。和 Skill 的按需加载相比,传统 RAG 是先全量准备好,再一次给予的范式。
Skill 式方案的优势
和传统 RAG 比,这套在下面几方面更占便宜。
和 Skill 同源的渐进式加载
先读索引再定范围,先学处理方法再动文件,每轮只加载一小段上下文,不够再迭代。不一次性把整库或整文件灌进上下文,模型看到的内容更聚焦,也更容易按「哪一步读了什么」来溯源。
零向量依赖,上手成本低
不接 embedding 服务、不建向量库、不调 chunk 和 top-k。有 grep、能读文件、能跑 pdftotext/pdfplumber/pandas 就能用。适合「先跑通再优化」的本地或内网环境。
维护简单,改目录即改检索
新加文档只要放进对应目录,在 FileIndex.md 里补一两句说明即可,不用重算向量、重建索引。目录结构就是检索结构,人好懂、也好改。
可解释、可溯源
回答能直接落到「某文件、某页/某行附近」,用户能自己去原文对。传统 RAG 经常只能说是「和问题最相似的几段」,很难精确到页码和行号。
表格和结构化数据更友好
Excel 用 pandas 按列按条件查,保留行列语义;PDF 里的表用 pdfplumber 提表再检索。传统 RAG 把整表当长文本切块,表格结构容易丢,查「某指标、某条件」不如这种按表查来得准。
「先学再动手」少踩坑
规则强制:动 PDF/Excel 前必须先读 references 里对应文档。模型会按既定方法处理(比如 PDF 提到文件、Excel 用 nrows 限制),减少瞎试和整文件灌上下文。
多轮迭代,而不是一锤子买卖
最多 5 轮检索,可以换关键词、换文件、收窄或扩大范围。找不到就再试一轮,比一次 top-k 定生死更稳。
和传统 RAG 的对比(说人话版)
| 维度 | 传统 RAG(向量检索) | 分层索引导航 + 渐进式检索(我们这套) |
|---|---|---|
| 找「该看哪」 | 用问题的向量在向量库里找最相似的 chunk | 读各层 FileIndex.md,按目录和用途选目录/文件 |
| 找「具体段落」 | 相似度 top-k,一次拿 k 个块 | 在选定文件里 grep 关键词,按行号局部 read,可多轮迭代 |
| 是否用 embedding/向量库 | 要,且要选模型、建索引、维护 | 不用,零向量组件 |
| 依赖 | 向量 DB、embedding 服务/模型、chunk 策略 | grep、按行读文件、pdftotext/pdfplumber、pandas 等,都是本地常见工具 |
| 文档更新 | 新文档要切块、算向量、写库,有时要重训或调参 | 新文档放进目录、改一下对应 FileIndex.md 即可 |
| 可解释性 | 一般是「这几段和问题最相似」,不好直接对应到「第几页、第几行」 | 可以明确说:来自某文件、某页/某行附近,便于核对和溯源 |
| 适合的问法 | 开放、换一种说法也能找到「意思差不多」的 | 更适合有明确关键词、或能通过索引缩小到某几类文件的问题 |
| 表格/结构化数据 | 通常当文本切块,表格结构容易丢 | 用 pandas 按列/行过滤,保留表格语义,适合「查某个指标、某条件的数据」 |
传统 RAG 是算相似度、从大池子里捞一堆块;我们这套是看目录索引锁定目标,再用关键词和局部读取在少数文件里精挖。
适用场景怎么选
- 文档多、问法杂、强调「意思相近」:上传统 RAG 更合适,语义检索能兜住各种换说法。
- 文档按目录/领域分得好,问题里常有明确关键词或文件名/类型:分层索引 + 渐进式检索就够用,实现简单、不依赖向量服务,本地就能跑。
- 强需求「这段话在哪一页、哪一行」:我们这套更容易给出精确引用;传统 RAG 要额外做 chunk 到原文位置的映射。
- 大量 Excel/报表类:按列筛选、按条件过滤更适合「先学再查表」这种方式;传统 RAG 把表当长文本切,容易丢结构。
当前方案的不足
说下短板,方便按自己的场景取舍。
比较费 token
虽然强调「局部读取、不整文件灌」,但整条链路还是会吃掉不少 token:要读各层 FileIndex.md 做导航,处理 PDF/Excel 前要读 references,多轮检索每一轮都有 grep 结果和局部片段的读写。问题复杂、涉及多目录多文件时,几轮下来 token 会明显上去。和「一次向量检索 + 固定 top-k 段」比,我们这条路在单次请求 token 量上不一定更省,只是把成本摊在了「索引 + 多轮精查」上。
大模型有时不会激活这个 Skill
Skill 的触发依赖模型对「要不要用知识库检索」的判断,通常靠描述里「从知识库查」「检索信息」「查资料」等关键词来匹配。用户问法如果偏泛(比如「聊聊 AI 趋势」)、没提「查一下」「帮我找」之类,模型可能直接用自己的知识答,不会走 Skill,也就不会去读你的 FileIndex.md 和文件。要查本地知识库时,问法里带一点「从知识库/从文档里查」「检索一下」,或者直接在问题里点明领域/文件名,触发会更稳定。
依赖离线批量写好索引
检索质量很大程度取决于 FileIndex.md 写得好不好。索引写得太简略或和实际文件对不上,模型会选错目录/文件,后面再精查也救不回来。省了向量那套,就得在索引维护上多花点心思。
写在最后
设计思路来自 Skill 的渐进式加载:不一次性全量加载,而是按需、分层、分轮地把「该看的索引 → 该学的方法 → 该读的片段」一点点加载进来。不建向量库也能在本地知识库(PDF/Excel/Markdown)里做检索和问答,零向量依赖、易维护、可解释、表格友好。要接受的是:会相对费 token、模型不一定每次都会激活这个 Skill(问法里最好带一点「查知识库」的意图)、检索效果依赖人工把索引写好。
和传统 RAG 是两条路。传统 RAG 是全量预处理 + 一次 top-k,适合开放域、问法多样;我们这条是 Skill 式的渐进加载进知识库,适合目录清晰、想少维护、要可溯源。能接受上面这些不足的话,可以试试这条路径;要应对千奇百怪的问法、大规模开放语料,再上向量 RAG 更稳。
我自己测试下来,把目录和 FileIndex.md 写清楚之后,查 PDF、Excel 比想象中顺手;问法里带一句「从知识库查」或点明文件名,触发会稳很多。如果你也在做本地知识库,可以从「按需加载」这个念头出发:先给目录写几份 FileIndex.md,再按文件类型定几条「怎么读、怎么查」的规矩。